Machine learning es una rama de la inteligencia artificial que permite a las computadoras aprender automáticamente a partir de datos y algoritmos para identificar patrones, hacer predicciones o tomar decisiones.

En el mundo actual, donde la tecnología avanza a pasos agigantados, términos como inteligencia artificial (IA) y aprendizaje automático (machine learning) se han vuelto cada vez más comunes. Sin embargo, es habitual que surjan dudas sobre las diferencias entre ambos conceptos, así como sobre su funcionamiento y aplicaciones.
Una de las preguntas más comunes al iniciar en el campo de la inteligencia artificial es: ¿cuál es la diferencia entre las técnicas de inteligencia artificial y el aprendizaje automático? Para responder a esta pregunta, es importante tener presente que la inteligencia artificial es un campo amplio que engloba diversas técnicas y métodos cuyo objetivo es crear sistemas capaces de realizar tareas que normalmente requieren inteligencia humana, como razonar, aprender o entender el lenguaje. Dentro de estas técnicas se encuentra el aprendizaje automático (machine learning).
Si te interesa dominar este tipo de tecnologías, la Maestría en Inteligencia Artificial de UNIR México te ofrece una formación avanzada, enfocada tanto en los fundamentos teóricos como en las aplicaciones prácticas de la IA. Con un enfoque multidisciplinario y 100% en línea, podrás desarrollar habilidades clave en machine learning, deep learning, visión artificial y procesamiento del lenguaje natural, preparándote para liderar proyectos tecnológicos de alto impacto.
Qué es machine learning o aprendizaje automático
Como se muestra en el diagrama de Göçer (2020), el aprendizaje automático es una disciplina dentro de la inteligencia artificial, encargada de diseñar algoritmos que permiten a las máquinas aprender de los datos y mejorar su desempeño sin necesidad de ser programadas explícitamente para cada tarea.
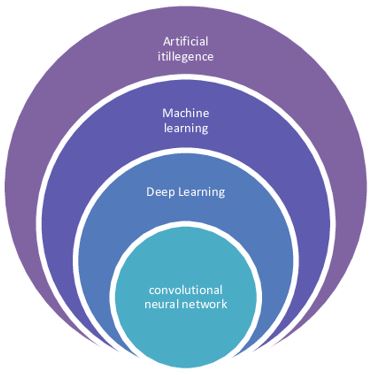
Figura 1. Relación entre inteligencia artificial, aprendizaje automático, aprendizaje profundo y ciencia de datos. Fuente: Göçer (2020), tomado de
ResearchGate.
Una de las definiciones más aceptadas de aprendizaje automático fue propuesta por Tom M. Mitchell (1997), quien estableció que:
“Se dice que un programa de computadora aprende de una experiencia E respecto a una clase de tareas T y una medida de rendimiento P, si su rendimiento en las tareas de T, medida por P, mejora con la experiencia E” (Mitchell, 1997).
Cómo funciona el aprendizaje automático
El aprendizaje automático es una rama de la inteligencia artificial que permite a los sistemas aprender a partir de datos, sin ser explícitamente programados para cada tarea específica. Esto significa que, en lugar de escribir instrucciones detalladas para que un sistema realice una acción particular, se le proporciona un conjunto de datos y algoritmos que le permiten identificar patrones. Su propósito es resolver problemas donde escribir un programa tradicional resulta complejo, como por ejemplo la detección de spam, diagnóstico médico o predicción de fraudes.
Para entender mejor cómo funciona el aprendizaje automático y en qué se diferencia del enfoque tradicional, imaginemos que queremos crear un sistema que clasifique números como pares o impares.
En el enfoque tradicional, se definen reglas explícitas: se le indica al sistema que tome un número, lo divida entre dos y, si el residuo es cero, entonces el número es par; si no, es impar. Aquí las reglas se establecen de forma precisa y sin ambigüedad.
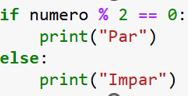
Ejemplo de código en Python para clasificar números pares e impares.
Este tipo de solución funciona perfectamente en situaciones donde las reglas son claras y fáciles de definir.
Sin embargo, ¿qué ocurre si la tarea es más compleja? Por ejemplo, si se desea que un sistema reconozca si un correo es spam o no spam. En este caso, no existen reglas tan simples. Se podrían escribir condiciones como: “si el correo contiene las palabras ‘gratis’ o ‘oferta’, es spam”, pero pronto nos daríamos cuenta de que los correos son demasiado variados para cubrir todos los casos.
Aquí es donde entra el aprendizaje automático: en lugar de definir reglas, se deben recopilar muchos ejemplos de correos etiquetados como spam o no spam. El modelo aprende de los datos y detecta patrones y una vez que ha sido entrenado, el sistema puede clasificar correos nuevos que nunca ha visto antes.
El problema abordado en este documento es un caso de aprendizaje supervisado, donde el modelo aprende a partir de datos etiquetados (por ejemplo, correos marcados como spam o no spam). Sin embargo, existen también enfoques no supervisados, donde los datos no tienen etiquetas y el modelo debe encontrar patrones por sí mismo, como en la segmentación de clientes o la detección de anomalías.
Características del machine learning
A continuación, se presentan algunas características del aprendizaje automático en comparación con el enfoque tradicional, basadas en diversos autores:
| Aspecto | Enfoque tradicional | Aprendizaje automático |
|---|---|---|
| Lógica de decisión | Definida manualmente mediante reglas fijas. (Géron, 2019) | Aprendida a partir de los datos. (Géron, 2019; Mitchell, 1997) |
| Adaptabilidad | No se adapta a cambios en los datos o atributos. | Se adapta a nuevos datos o patrones cambiantes. (Goodfellow et al., 2016) |
| Ejemplo típico | Clasificar números como pares o impares (regla matemática fija). | Clasificar correos como spam o no spam (patrones complejos y variables). |
| Tipo de problema | Adecuado para problemas con reglas claras y predecibles. | Ideal para problemas con patrones complejos o cambiantes. (Bishop, 2006; Goodfellow et al., 2016) |
| Mantenimiento | Necesita actualizarse manualmente. | Aprende con nuevos datos o atributos. (Mitchell, 1997) |
| Requerimiento de datos | No necesita grandes volúmenes de datos | Necesita datos etiquetados para entrenar. (Bishop, 2006) |
| Ingeniería de atributos | No aplica, las reglas ya contemplan los atributos necesarios. | Requiere ingeniería de atributos manual. En deep learning, este proceso es automático.(Goodfellow et al., 2016) |
Como se observa en la comparación, el aprendizaje automático se diferencia del enfoque tradicional en su capacidad para aprender directamente de los datos, adaptarse a nuevas situaciones y manejar problemas complejos que no pueden resolverse mediante reglas fijas. Además, el deep learning automatiza la ingeniería de atributos, lo que permite abordar problemas aún más desafiantes siempre que se disponga de suficientes datos y capacidad computacional.
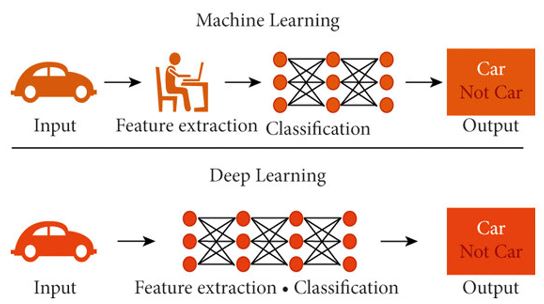
Figura 2. Diferencia entre aprendizaje automático y aprendizaje profundo. Fuente: Alzubaidi et al. (2021), tomado de ResearchGate
Algoritmos de machine learning
Los algoritmos de machine learning son las bases que permiten a las computadoras aprender automáticamente a partir de datos. Existen diferentes tipos, como los supervisados, no supervisados y de aprendizaje por refuerzo, cada uno diseñado para resolver distintos tipos de problemas, como clasificar imágenes, predecir tendencias o encontrar patrones ocultos.
Modelos de machine learning
Un modelo de machine learning es el resultado de aplicar un algoritmo a un conjunto de datos para que la máquina aprenda una tarea específica. Estos modelos se entrenan y ajustan hasta que logran hacer predicciones precisas o identificar relaciones complejas. Son fundamentales para tareas como diagnósticos médicos automatizados o motores de recomendación.
Ejemplos de aprendizaje automático
El aprendizaje automático está presente en muchas herramientas que usamos a diario. Estos son algunos ejemplos de su uso:
- Filtros de spam en correos electrónicos que aprenden a identificar mensajes no deseados.
- Sistemas de recomendación en plataformas como Netflix o YouTube, que sugieren contenido basado en tus gustos.
- Predicción de compras en e-commerce, para ofrecer productos según tu comportamiento anterior.
- Reconocimiento facial en dispositivos móviles o aplicaciones de seguridad.
- Detección de fraudes en transacciones bancarias en tiempo real.
- Conducción autónoma, donde el vehículo aprende a interpretar su entorno y tomar decisiones.
- Diagnóstico médico asistido, usando imágenes o historiales clínicos para detectar enfermedades.
Aplicación del aprendizaje automático en inteligencia artificial
El aprendizaje automático es una de las técnicas más poderosas dentro del campo de la inteligencia artificial. Gracias a él, los sistemas pueden analizar grandes volúmenes de datos, adaptarse al cambio y mejorar su desempeño con el tiempo. Esto permite desarrollar asistentes virtuales, sistemas de conducción autónoma o herramientas de análisis predictivo, entre otros avances.
En resumen, el aprendizaje automático representa una evolución frente a los enfoques tradicionales, en los que se requiere definir manualmente las reglas que permiten resolver un problema. El método tradicional funciona bien para situaciones claras y predecibles, pero resulta insuficiente para el manejo de patrones complejos o dinámicos. El aprendizaje automático, en cambio, permite a los sistemas aprender directamente de los datos, adaptarse a nuevas condiciones y detectar patrones que no podrían ser programados de manera explícita. Además, con el desarrollo de deep learning, se ha automatizado la ingeniería de atributos, lo que permite abordar problemas aún más complejos sin necesidad de intervención manual. Así, el aprendizaje automático se ha convertido en una herramienta esencial para resolver problemas reales en contextos dinámicos y diversos.
Autora:
Patricia Rayón Villela
Coordinadora de titulación. Escuela de Ingeniería y Tecnología México.
Referencias
- Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32.
- Géron, A. (2019). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems. O’Reilly Media.
- Ghanbari, E., & Najafzadeh, S. (2022). Machine learning. In Machine Learning and Big Data. Department of Computer, Islamic Azad University.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
- Mitchell, T. M. (1997). Machine learning. McGraw-Hill.
- Vapnik, V. N. (1995). The nature of statistical learning theory. Springer.