Deep learning o aprendizaje profundo, es una rama de la IA que utiliza redes neuronales. Conoce cómo funciona y sus aplicaciones.

El deep learning o aprendizaje profundo es una rama del aprendizaje automático que permite a las computadoras aprender directamente de los datos a través de redes neuronales profundas. Esta técnica ha sido clave en muchos de los avances recientes de la inteligencia artificial (IA), desde los asistentes virtuales hasta los coches autónomos.
¿Qué es el Deep Learning?
El término deep (profundo) hace referencia a la cantidad de capas ocultas en una red neuronal artificial. A diferencia de los modelos de aprendizaje automático tradicionales que dependen de características obtenidas “manualmente”, el deep learning puede aprender representaciones complejas a partir de grandes volúmenes de datos.
Uno de los pioneros en este campo es Geoffrey Hinton, considerado el “padrino del deep learning”. En 2006, Hinton y su equipo revivieron el interés por las redes neuronales profundas al mostrar que podían entrenarse eficazmente usando un enfoque jerárquico llamado preentrenamiento capa por capa.
El aprendizaje profundo (deep learning) no es un campo aislado, sino parte de una jerarquía dentro de la inteligencia artificial (IA).
- Inteligencia Artificial (IA): Ciencia que estudia cómo crear sistemas que simulen inteligencia humana.
- Aprendizaje Automático (Machine Learning): Subcampo de la IA enfocado en algoritmos que aprenden a partir de datos sin programación explícita.
- Aprendizaje Profundo (Deep Learning): Rama del machine learning basada en redes neuronales profundas, capaz de aprender representaciones complejas.
- Aprendizaje Profundo Generativo (Generative Deep Learning): Subárea del deep learning centrada en modelos que pueden generar contenido nuevo, como texto, imágenes, voz o música.
¿Cómo funciona el Deep Learning?
El aprendizaje profundo se basa en redes neuronales artificiales organizadas en muchas capas, de ahí su nombre. Estas redes funcionan a través de un proceso de aprendizaje supervisado, ajustando sus parámetros para minimizar el error de predicción. A diferencia de las redes neuronales tradicionales estas requieren de millones de datos para aprender la tarea a realizar.
Aprender, en este contexto, significa ajustar internamente los “pesos” de conexión entre las neuronas cada vez que la red comete un error. Este proceso es similar al modo en que una persona mejora con la práctica: tras cometer errores y recibir retroalimentación, ajusta su estrategia para obtener mejores resultados. Así, la red mejora su desempeño al analizar miles o millones de ejemplos.
Estructura básica de una red neuronal profunda
Una red neuronal profunda típica está compuesta por tres tipos de capas:
- Capa de entrada (input layer)
- Esta capa recibe directamente los datos (por ejemplo, los píxeles de una imagen o las palabras de una frase) y la distribuye a la siguiente capa.
- Capas ocultas (hidden layers)
- Estas capas transforman la información y aplican funciones no lineales conocidas como funciones de activación, como por ejemplo ReLU, tanh, etc. Esta no linealidad permite que la red aprenda representaciones complejas de la tarea a realizar.
- Capa de salida (output layer)
- Esta capa es la que se encarga de generar la predicción final, ya sea una clasificación, una probabilidad, una palabra, etc., dependiendo del tipo de tarea a realizar.
Aunque esta arquitectura general se mantiene en casi todas las redes neuronales profundas, las capas ocultas pueden tener arquitecturas específicas según la tarea: convolucionales para imágenes, recurrentes o de atención para texto, o incluso combinaciones más complejas en modelos generativos.
Estas capas están conectadas entre sí mediante pesos, que son valores numéricos ajustables y representan el conocimiento aprendido por la red. Estos pesos se determinan tras un proceso intensivo de entrenamiento con grandes volúmenes de datos, utilizando una regla de aprendizaje (como el descenso de gradiente) que permite modificarlos progresivamente para reducir el error. Una vez que la red ha aprendido la tarea, es capaz de realizar predicciones sobre datos nuevos que no ha visto antes. Por ejemplo, puede reconocer imágenes de gatos o perros distintas a las utilizadas durante el entrenamiento.
Tipos de redes neuronales en deep learning según la tarea
Aunque todas las redes neuronales profundas comparten una estructura general —con capas de entrada, procesamiento y salida—, la arquitectura específica de la red varía significativamente según el tipo de datos y la tarea a resolver. En el aprendizaje profundo, existen distintos tipos de redes especializadas, como convolucionales, recurrentes o basadas en atención, que se adaptan mejor a problemas como visión por computadora, procesamiento de lenguaje natural, análisis de audio o generación de contenido. A continuación, se describen las arquitecturas más utilizadas para cada uno de estos dominios.
. En todos los casos, las capas ocultas están diseñadas específicamente para el tipo de entrada y la salida deseada, y su profundidad y arquitectura varían en función de la tarea: clasificación, predicción, reconstrucción o generación
Imágenes (visión por computadora)
Las CNN (redes convolucionales) fueron durante mucho tiempo la arquitectura dominante en visión por computadora. Algunos modelos populares son: AlexNet y ResNet. Actualmente existen otras arquitecturas gracias al avance de los transformers y modelos híbridos, los Vision Transformers (ViT) los cuales utilizan mecanismos de autoatención, sin convoluciones, o finalmente los modelos híbridos (CNN + atención) que combinan convoluciones para capturar detalles locales con atención para contexto global, un ejemplo de esta es: ConvNeXt, CoAtNet.
Estas redes pueden reconocer tu rostro o realizar un diagnóstico en una imagen médica.
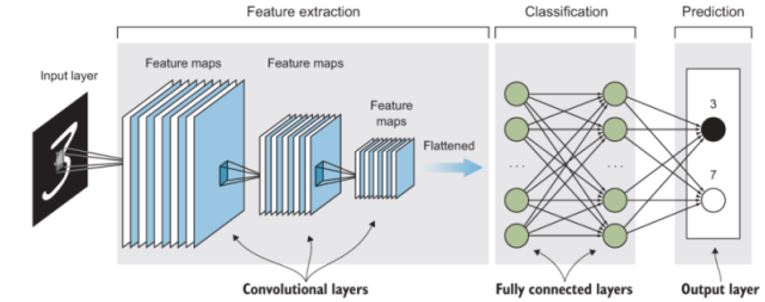
Figura 1. La arquitectura CNN consta de: capa de entrada, capas convolucionales, capas completamente conectadas y predicción de salida.
Texto (procesamiento de lenguaje natural)
Se emplean redes recurrentes (como LSTM o GRU) o Transformers, cuyas capas están diseñadas para modelar secuencias, relaciones contextuales y dependencias a largo plazo. Cada capa puede representar el significado progresivo de una palabra en contexto. Algunos modelos son BERT, RoBERTa (codificadores para comprensión) y T5, BART (encoder-decoder para traducción y resumen). Estas redes son la base de asistentes como ChatGPT o traductores automáticos como Google Translate
Voz o audio (señales temporales)
Pueden utilizarse CNN aplicadas a espectrogramas o arquitecturas recurrentes para capturar patrones de frecuencia y ritmo en el tiempo. Existen algunos modelos recientes como Wav2Vec 2.0 (Facebook AI) y Whisper (OpenAI) que están revolucionando el reconocimiento automático de voz.
Este tipo de redes permiten que los asistentes por voz entiendan comandos hablados como “llamar a casa”-
Modelos generativos (aprendizaje profundo generativo)
Los modelos generativos funcionan como artistas digitales: pueden imaginar y crear contenido nuevo a partir de lo aprendido. Para lograrlo, utilizan arquitecturas específicas según el tipo de tarea. Algunas redes, como las GANs, transforman vectores aleatorios en imágenes realistas; otras, como los VAEs, comprimen y reconstruyen información desde un espacio intermedio; y los transformers generativos, como GPT o DALL·E, procesan secuencias complejas para producir texto, imágenes u otros contenidos novedosos. (como GPT o DALL·E), cada capa es un bloque compuesto por mecanismos de autoatención y redes densas, y se repiten muchas veces (hasta 96 o más capas), permitiendo generar texto o imágenes complejas desde una secuencia de entrada.
Aplicaciones del Deep Learning
El aprendizaje profundo se aplica en una amplia variedad de campos. En visión por computadora, permite reconocer objetos, rostros y diagnóstico o detección de anomalías médicas en imágenes con alta precisión. En el procesamiento de lenguaje natural, se utiliza para traducir textos, generar resúmenes, responder preguntas y crear asistentes virtuales inteligentes. En el reconocimiento de voz, convierte audio en texto y permite el control por voz en dispositivos. Los sistemas de recomendación ofrecen sugerencias personalizadas basados en el comportamiento del usuario. La creación de logos o paisajes, la generación de resúmenes, diseño de moléculas son otras aplicaciones destacadas.
El impacto del aprendizaje profundo ha sido reconocido más allá del ámbito académico. En 2024, los avances en redes neuronales profundas fueron destacados con el Premio Nobel de Física, otorgado por sus contribuciones a la modelización computacional de sistemas complejos y al desarrollo de herramientas fundamentales para la inteligencia artificial moderna. Esta distinción se suma a otros reconocimientos importantes como el Premio Turing (2018) que fueron concedidos a Geoffrey Hinton, Yoshua Bengio y Yann LeCun, considerados los padres del deep learning. Su trabajo ha impactado profundamente campos como la medicina, la industria, la educación y la comunicación, reafirmando al aprendizaje profundo como una de las tecnologías más transformadoras de nuestro tiempo.
Autora
Dra. Patricia Rayón Villela
Área de Ingeniería y Tecnología
Coordinadora de la Maestría en Inteligencia Artificial de UNIR México
Referencias bibliográficas
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. https://www.deeplearningbook.org
- Foster, D. (2020). Generative Deep Learning: Teaching Machines to Paint, Write, Compose, and Play. O’Reilly Media.
- Chollet, F. (2021). Deep Learning with Python (2nd ed.). Manning Publications.
- Alpaydin, E. (2020). Introduction to Machine Learning (4th ed.). MIT Press.