La visión artificial es una rama de la inteligencia artificial que permite a las máquinas interpretar imágenes o videos del mundo real. Se usa en aplicaciones como reconocimiento facial, inspección industrial o conducción autónoma.

Cuando un bebé nace, su visión es borrosa y confusa. Con el tiempo, su cerebro aprende a darle sentido a las formas. Este proceso de aprendizaje es complejo y asombroso. Ahora, imagina si pudiéramos enseñarle a una máquina a hacer lo mismo: a no solo “ver” una imagen, sino a comprenderla. Esto es precisamente lo que hace la visión artificial, una de las ramas tradicionales de la inteligencia artificial. Su objetivo es entrenar a las computadoras para interpretar y comprender el mundo visual a partir de imágenes y videos, transformando arreglos de datos en información útil. La visión artificial ya forma parte de nuestra vida cotidiana, operando discretamente en nuestros teléfonos, autos y hasta en los supermercados.
Los fundamentos: de píxeles a patrones
Para un humano, una fotografía es la escena de un perro o un edificio. Para una computadora, esa misma foto es simplemente una colección de números organizados en pequeños cuadros llamados píxeles.
Cada píxel tiene un valor numérico que indica su color o intensidad. En una foto a color, por ejemplo, cada píxel se representa con tres números (rojo, verde y azul). Esto significa que, aunque nosotros vemos formas y objetos, la máquina solo ve arreglos de números. El gran reto de la visión artificial es desarrollar algoritmos capaces de transformar esos números en información útil, pasando de ver píxeles a ver objetos.
Cómo ha evolucionado la visión artificial
En sus inicios (años 70–90), la visión artificial dependía de métodos clásicos: filtros, detección de bordes y reglas diseñadas manualmente. Estos métodos, aunque útiles para tareas simples como distinguir contornos, eran muy limitados.
El gran cambio llegó con el aprendizaje automático (machine learning) y, más recientemente, con el aprendizaje profundo (deep learning). Esta tecnología imita el funcionamiento de las neuronas del cerebro humano, permitiendo a los sistemas, a través de redes neuronales convolucionales (CNNs), aprender directamente de millones de imágenes para distinguir patrones complejos por sí solos.
Gracias a esto, los algoritmos pueden diferenciar un rostro humano, detectar un tumor en una radiografía o guiar a un vehículo autónomo en la carretera.
El proceso: de la captura a la interpretación
De forma general, la visión artificial sigue un ciclo de varias etapas para transformar los datos visuales en significado:
- Captura de la imagen: una cámara o sensor obtiene la información visual.
- Preprocesamiento: se limpia y mejora la imagen (ajuste de contraste, escala de grises, eliminación de ruido).
- Extracción de características: el sistema identifica patrones relevantes como bordes, formas o texturas.
- Clasificación o segmentación: el modelo entrenado asigna etiquetas a los objetos (“esto es un perro” o “este es un edificio”).
- Interpretación: se produce el resultado final y útil.

Figura 1. Ejemplo ilustrado de la etapa de captura, preprocesamiento y extracción de características.
Ejemplo detallado: el reconocimiento de caracteres (OCR)
Una aplicación muy común que ilustra estas etapas es el reconocimiento óptico de caracteres (OCR), utilizado en herramientas como Google Lens o en aplicaciones de escaneo de documentos.
Cuando, por ejemplo, contamos con una imagen de un recibo, primero se realiza el preprocesamiento de la foto. Luego, en la extracción de características y segmentación, se detectan los contornos del texto y se aíslan los caracteres individuales. En este punto solo se cuenta con “objetos” separados que el sistema debe reconocer.
Posteriormente, en la clasificación, el sistema utiliza un modelo entrenado (como una red neuronal) para predecir con alta probabilidad qué letra o número corresponde a cada contorno. Finalmente, el sistema une los caracteres reconocidos para generar un texto digital editable.
Este proceso convierte una simple foto en una respuesta interpretada, pasando de números a significados útiles.
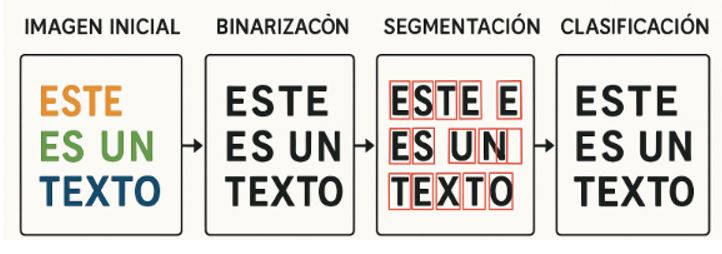
Figura 2. Etapas de un OCR: a) captura de la imagen, b) preprocesamiento, c) segmentación, y d) clasificación.
Aplicaciones
La capacidad de “ver” de las máquinas ha llevado a la visión artificial a revolucionar industrias enteras y nuestra vida diaria:
- Seguridad y hogar: reconocimiento facial para desbloquear celulares y sistemas de vigilancia inteligentes que detectan comportamientos anómalos en tiempo real.
- Medicina: análisis de imágenes médicas (radiografías, resonancias) que ayudan a detectar tumores y enfermedades con mayor rapidez y precisión.
- Industria y comercio: control de calidad con sistemas que inspeccionan productos en una línea de producción. En tiendas, la visión artificial rastrea artículos para eliminar la necesidad de pagar en caja.
- Transporte: los vehículos autónomos dependen de la visión artificial para identificar peatones, señales de tráfico y otros vehículos, permitiéndoles tomar decisiones críticas.
- Agricultura: drones que analizan cultivos y detectan plagas o necesidades específicas de riego.
La visión artificial no busca reemplazar la visión humana, sino complementarla. Al enseñarle a las máquinas a interpretar el mundo visual, estamos creando soluciones que mejoran nuestra seguridad, salud y eficiencia.
En el futuro, la capacidad de una computadora para ver y comprender será tan relevante como su capacidad para procesar datos, transformando continuamente la forma en que interactuamos con la tecnología y el mundo que nos rodea.